Global Happiness
After a little consideration I’ve decided to pursue the Global Happiness Index project I wrote about on Friday. I registered GlobalHappiness on Twitter, so I think I’ll just skip talking about “index” from now on. To be honest, I was a bit surprised that GlobalHappiness wasn’t already registered by someone else. What about starting to follow GlobalHappiness today? Great idea!
Of course, only collecting data from Twitter won’t actually show the actual global happiness. It will show the happiness among Twitter users, people with an internet connection and a sometimes unhealthy need to share. Take myself for instance. Still, with the massive amount of tweets that are coming in, it will at least give some indication of how people feel globally. Another good reason to use Twitter is how extremely easy they make it to access the public time line. It’s a simple GET request and everything I need is available. But what to do with all that data?
At first, I wanted to just query the public time line every minute and look for the words “happy” and “sad” and synonyms for those words. But there are a number of problems with this approach. The the word “great”, for instance. It’s a synonym for “happy” but “great” can also mean a lot of other things as well, not just “great” as in “I’m feeling great” and the probe will quickly begin to collect tweets like the two below and register them as positive tweets.
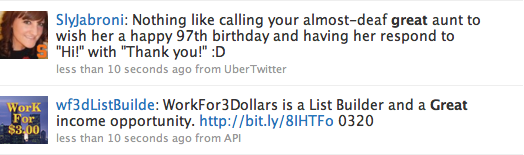
I want the data collection to be fully automatic, without the need for manually checking data quality or ignoring certain Twitter users. This means I need a better way to get data and this is possible by searching for specific words instead of just looking at the entire public time line. By limiting the number of tweets to process to only tweets containing the phrase “I feel”, and then look for words associated with feelings, the probe can potentially remove a lot of noise and garbage data. But it’s still not good enough and data like the tweets below will get collected by the probe:
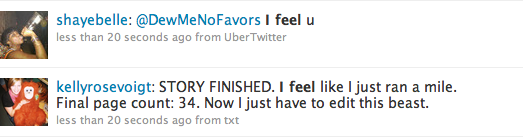
Both these tweets would be ignored by the probe because they don’t contain any words associated with feelings, but it’s still garbage that I’d like to avoid. To remove these and filter out even more tweets, I will mostly likely do as the people who put together We Feel Fine. They are limiting their search to sentences that contain the phrase “I’m feeling” and a search on Twitter shows that this is a very good phrase to use. The data available data is limited, but not too small, and the data quality isn’t too bad.
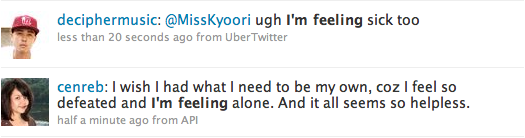
A quick look through some of the search results also shows that people are generally not feeling very well right now. So, what are the next steps? First, it’s probably a good idea to get a white listing from Twitter so that I don’t hit their request rate limit during development phase, which tends to be a lot of trial and error. Then, I need to dig up a PHP framework that can handle one of the many response formats from Twitter, configure a database and collect a load of happy and sad words to search for. When the probe is working and is collecting data, it will be interesting to see what comes in and if it’s possible to use it for anything at all.
This might turn out to be a lot of fun. Or another project that slowly fades away into oblivion. We’ll see!
Feedback
This post has no feedback yet.
Do you have any thoughts you want to share? A question, maybe? Or is something in this post just plainly wrong? Then please send an e-mail to vegard at vegard dot net with your input. You can also use any of the other points of contact listed on the About page.
